


Written by Emilio Cammarata (Trainee Data Management at ODISSEI) and Angelica Maineri (Data Manager at ODISSEI)

The aim of this short article is to explore the possible uses of ontologies, as developed in philosophy first and in computer sciences later, and why they are relevant for the social sciences. After defining what an ontology is, we provide a very minimal yet practical example to illustrate the use of the tool. We conclude by explaining possible applications of ontologies for the FAIRification of social science research, and introducing you to the Awesome List of Ontologies for the Social Sciences.
The “I” in FAIR stands for Interoperability, and it means that not only a human but also a machine needs to be able to communicate, interpret and share information with other agents. Interoperability has been defined in the founding article of FAIR principles as “the ability of data or tools from non-cooperating resources to integrate or work together with minimal effort” [1, p. 2]. Interoperability thus requires to integrate digital objects or systems in a standard way, so that the meaning of those objects can be understood and processed by different applications.
The Interoperability principle encourages the use of structured vocabularies, namely curated collections of terms and relationships among them. There are different flavours of such structured vocabularies, and in a previous short article from the ODISSEI FAIR support series [2], we went through the concepts of controlled vocabularies, taxonomies and thesauri, which are structured vocabularies with a relatively limited array of relationships among terms, for instance “it is broader than” or “it is equivalent to”. There are situations where you need to be able to describe more complex, semantically-rich relationships among entities: for instance, you may want to represent that a person “is a member of” a group, or that a student “is enrolled in” a course: for these uses, you need ontologies.
Ontologies: what are they?
A (computational) ontology is a ‘formal, explicit specification of a shared conceptualization’ [3,p.2] or a description of the meaning of the data, which is provided in an uniform way in order to be understood by different people (or machines) [4]. In other words, an ontology consists of a set of concepts, represented by terms, and of relationships among these concepts. Unlike thesauri (see [2]), in which only specific types of relationships can be specified (i.e. hierarchy, association, equivalence), relationships specified in an ontology can have rich semantic qualifiers.a In this way, an ontology can represent complex and fine-grained relationships between concepts – ideally, all relationships pertaining to the act of being should be described, although, in practice, only the relevant ones in a specific domain are represented.
The ambition to represent all relationships pertaining to the act of being originates from the original meaning of the concept “ontology”. The term “ontology” can be translated as ‘the study of being’, the word derived from the ancient Greek ‘to on’, to be, and ‘logos’, which can be roughly translated as ‘to study’ [5]. In philosophy, it denotes the study of the most universal and essential attributes of being and it consists in the formulation of a definition of what is, namely what does exist in reality. The claim of God’s existence or of the presence of universal laws in the universe are two examples of ontological investigations [5]. One of the first ontological statements in the history of philosophy has been formulated by Parmenides in the fragments of his poem ‘On nature’ : “..it is possible for it to be, and it is not possible for what is nothing to be..” [6]. In this way Parmenides gave the most broad and generally applicable definition of ‘being’. Since then, a lot of philosophers focused on the study of being, or ontology, but the argument goes well beyond the scope of this blogpost. Therefore, if you are curious about the historical origin of the topic we suggest reading the webpage ‘Logic and Ontology’ on the website of the Stanford Encyclopedia of Philosophy.
More recently, the term ‘ontology’ has been borrowed in the field of computer sciences to represent the minimum unit of analysis of data knowledge, or the broadest accepted meaning of a concept. It is an interpretation of the world that is still strictly related to its philosophical meaning. For this reason, we have to emphasise that in computer sciences we are talking about particular types of ontologies, called ‘computational ontologies’ [3]. Nonetheless, for the sake of simplicity we will call them simply as ontologies throughout the text.
As mentioned in the introduction, ontologies belong to a set of structured vocabularies, including for instance controlled vocabularies, taxonomies and thesauri (see [2]). Let’s use a little example to understand the difference between thesauri and ontologies. Imagine you’re organising a bookshelf. In that case a thesaurus would list different words that are related or have similar meanings, like “dog” and “canine” or “happy” and “joyful”. It shows synonyms but doesn’t explain the relationships between the words. On the other hand, an ontology goes one step further, it builds a conceptual map of how different terms are related through their properties and relationships. For example, on top of specifying that a “dog” is a type of “canine” which is a type of “mammal” like a thesaurus or a taxonomy would do, an ontology would also specify that a dog “has” certain properties like “four legs” and is “capable of barking”.
An ontology typically consists of three componentsb:
- classes: the entities/concepts represented in the ontology, for instance “dog”
- relationships: the links between entities, for instance “has”, “is capable of” or “is a subclass of”
- attributes: the features of an individual class, for instance “has four legs” or “barking”.c
An ontology is a generalised model, which can be reused multiple times to represent different entities. In the words of Taye, we can state that ‘the goal of an ontology is to achieve a common and shared knowledge that can be transmitted between people and between application systems’, so there must be some degree of agreement on the specification of the ontologies in a community [4, p.185].
Example
The concept of (computational) ontology is difficult to understand without a practical example, so we will try to illustrate it with a simple one whereby we want to describe in a machine-readable manner who the authors of this blogpost are. For this, we make use of ontologies, and more specifically the FOAF (Friend Of A Friend) ontology (see FOAF Vocabulary Specification). FOAF is a broad set of ontologies and it is highly interlinked with the social science’s field of social network analysis. As a matter of fact, FOAF can be applied on the web to describe oneself, including one’s name, email address, and the people they’re friends with. FOAF is also widely used to describe the relationship between people and information on the web.
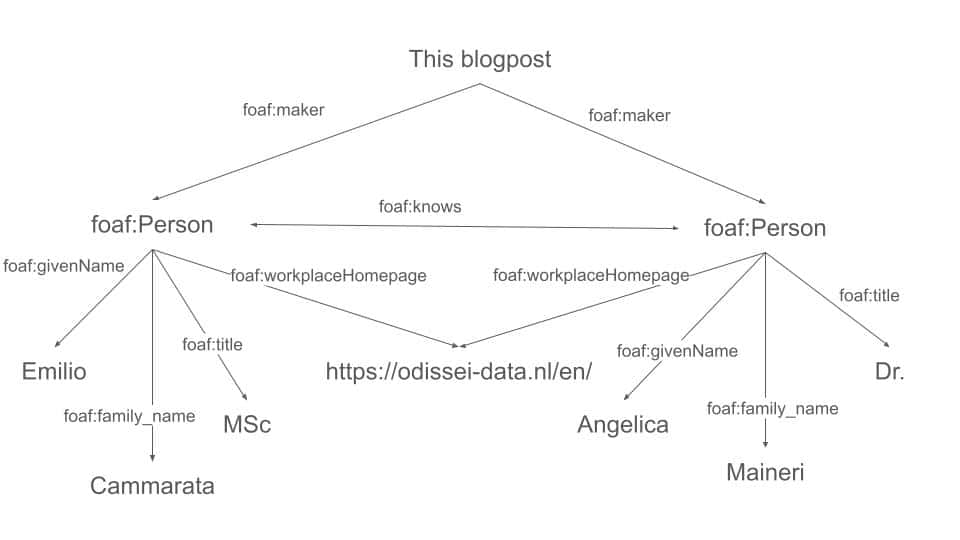
In Figure 1, we find a graph representing the authors of this blog post. The edges between the different nodes are semantically specified by the underlying ontology (indicated by “foaf:”), meaning that we can trace the meaning of “maker” or “know” back to a predefined specification: the one in the FOAF ontology.
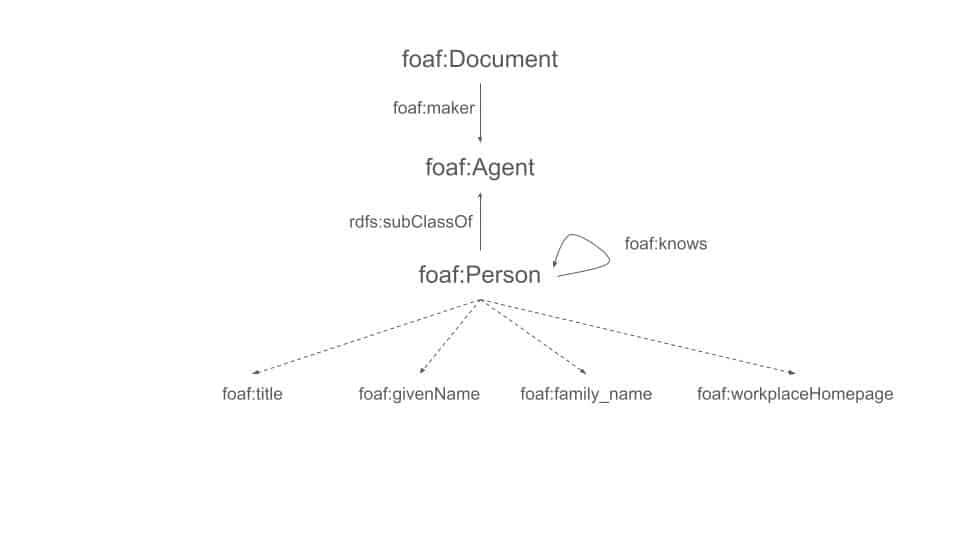
The underlying ontology is visually represented in Figure 2 below, and it looks similar to a network graph. The nodes represent the classes, or entities, and their properties. Classes start with a capital letter (e.g. Document, Person), unlike their properties, or attributes (e.g. firstName and family_name). It is standard practice to specify the name of the ontology in use followed by “:”, when applicable, hence the “foaf:” at the start of each node. The edges represent the relationships between entities. Dashed lines represent properties.
From FOAF, we know that an entity (class) “Document” like this blogpost can have an attribute (property) maker, namely “An agent that made this thing.” and from the official definition we also know that the maker is an Agent (“eg. person, group, software or physical artefact”). As we will illustrate, this can be helpful to know for data validation purposes. We also know that the makers of this blogpost are of type Person, which is a subclass of Agent. Note the prefix rdfs in “rdfs:subClassOf”: this is because “Is a subclass of” is a generic type of semantic relation which is described in the RDF schema vocabulary and therefore doesn’t need to be re-specified by FOAF. FOAF also specifies that the class Person can have different properties, including a title, a given name, a family name, and a workplace homepage. Moreover, a Person can know another person, where knows means “A person known by this person (indicating some level of reciprocated interaction between the parties).”.
While this way of expressing relationships between entities may look cumbersome for humans, they are exceptionally efficient for machines (and therefore fundamental for the application of the FAIR principles, in particular increasing interoperability). Suppose for instance that for a new research project you want to analyse the content of millions of blog posts using automated text analysis tools. An ontology offers a principled, formally sound, and flexible tool to organise information about those posts – for instance, extract the first and last names and titles of their makers – and generate data with a structure that can be easily queried and investigated using automated methods. If the model is then extended with new relations and attributes, they will inherit properties and relations from the description of reality embedded in the ontology specification.
Applications of ontologies
Once we represent our conceptualisation with an ontology, we have a consistent and agreed-upon way to represent ‘knowledge’ (e.g., data) in our community or organisation. This is helpful for:
– the community/organisation itself. It ensures consistency over time in the way the data is collected, processed and analysed, and also in the terminology used;
– the process of data validation. For instance, taking the example using the FOAF ontology, we know that an entity which is not a Person but, for instance, another Document, cannot be a maker because it is not an Agent. This can help prevent mistakes when entering/generating data.
– to exchange data with others. The information illustrates a relation between many concepts and it provides a framework to understand what is in the data using agreed-upon terminology. Therefore, it makes it easier to link data from different sources using the same terms to represent the same concepts. For instance, a machine may not be able to understand that “creator”, “author” and “maker” all indicate that someone created a document; it will, however, when it encounters “foaf:maker”.
The last point illustrates that for an ontology to be effectively used, in addition to clarity in its structure and conceptualisation, there must be a shared commitment by the community of use [4].d This means that governance aspects should be factored in when embarking in the process of designing a new ontology, as its meaning has to be validated by a community, and there should be clear processes in place to allow the community to propose additions and/or changes.
The Awesome List of Ontologies for the Social Sciences
Specifying a new ontology is a burdensome task, so it is recommended to first check whether an ontology exists that represents the concepts of interest.
How to find existing ontologies though? As previously said, many lists of ontologies are spread through the world wide web. For this reason, ODISSEI started a curated list of resources:
the Awesome list of Ontologies for the Social Sciences.e The repository lists ontologies, vocabularies and thesauri that are relevant for the social sciences. It also includes a section for look up services, which can help you retrieve even more resources. In the list, resources are grouped and include a link and a brief explanation. The repository is publicly accessible via github, allowing everyone not only to use it but also to contribute to it (see contribution guidelines) and keep it up to date.
For more information on the contribution guidelines and on the ontology list you can contact the authors of the blogpost at the following mail: fairsupport@odissei-data.nl.
References
[1] Wilkinson, M. D., Dumontier, M., Aalbersberg, Ij. J., Appleton, G., Axton, M., Baak, A., Blomberg, N., Boiten, J.-W., da Silva Santos, L. B., Bourne, P. E., Bouwman, J., Brookes, A. J., Clark, T., Crosas, M., Dillo, I., Dumon, O., Edmunds, S., Evelo, C. T., Finkers, R., … Mons, B. (2016). The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data, 3(1), 160018. https://doi.org/10.1038/sdata.2016.18
[2] Maineri. Angelica Maria. (2022). Controlled vocabularies for the social sciences: what they are, and why we need them. Zenodo. https://doi.org/10.5281/zenodo.7157800.
[3] Guarino, N., Oberle, D., & Staab, S. (2009). What is an ontology?. Handbook on ontologies, 1-17. In Staab, S., & Studer, R. (Eds.). (2010). Handbook on ontologies. Springer Science & Business Media.
[4] Taye, M. M. (2010). Understanding semantic web and ontologies: Theory and applications. arXiv preprint arXiv:1006.4567. URL: https://arxiv.org/ftp/arxiv/papers/1006/1006.4567.pdf.
[5] Hofweber, Thomas, “Logic and Ontology”, The Stanford Encyclopedia of Philosophy (Summer 2023 Edition), Edward N. Zalta & Uri Nodelman (eds.). URL: https://plato.stanford.edu/archives/sum2023/entries/logic-ontology/.
[6] Parmenides. On Nature. From John Burnet, Early Greek Philosophers. III edition. 1920. London: A&C Black. URL: http://platonic-philosophy.org/files/Parmenides%20-%20Poem.pdf.
Footnotes
(a) https://www.sciencedirect.com/topics/nursing-and-health-professions/controlled-vocabulary
(b) https://enterprise-knowledge.com/whats-the-difference-between-an-ontology-and-a-knowledge-graph/
(c) We will illustrate in a future blogpost how these elements can be easily encoded in triplets of the form <class, relation, attribute>
(d) See OBO Foundry (https://obofoundry.org/principles/fp-000-summary.html) for more guidance on how to ensure the quality of an ontology.
(e) The initiative was inspired by a similar initiative from CLARIAH (the Dutch infrastructure for Humanities) tailored to the digital humanities.
Relevant links
- Blog post on controlled vocabularies
- SSHOC-NL application
- Awesome Ontologies for the Social Sciences
Photo by Alina Grubnyak on Unsplash